A novel tool developed for a Fortune 500 Pharma and Biotechnology Corporation
 Copy Link
Copy LinkService providers:
Datopian
Client:
A fortune 500 company, one of the largest pharmaceutical corporations in the world, with a highly specialized Gene Research and Therapy division in Silicon Valley, California
Services:
Data Engineering, CKAN Development
Period:
2019 – 2021
Brief summary of the project
The project offers a compelling case for how Datopian created a custom-built discovery portal and search engine that streamlined processes, enabling a Fortune 500 pharmaceutical company to significantly improve dataset access and collaboration for their global research and development teams.
The client struggled with managing big amounts of clinical trial data from various sources, stored across their organization's numerous departments and geographical locations. The pharmaceutical company required a unified solution for data aggregation, a discovery portal, and a search engine that could incorporate their complex, organization-specific metadata language system.
The client needed a comprehensive solution to aggregate, search, and manage datasets across the organization, regardless of origin, storage, or geographical boundaries. They needed a solution that was both immediately useful and extremely customizable, allowing for seamless integration across their organization. The chosen solution had to be future-proof, supporting distributed deployment, interoperability with existing industry tools, and automation. Additionally, the solution needed to accommodate their unique dataset publishing domain model, sophisticated tagging system, and automated dataset uploading.
We developed a highly customized CKAN-based data portal and API serving system, tailored to the client's specific domain model and metadata language. The solution provided an intuitive user interface for data management, and a sophisticated API for automation and headless manipulation of datasets. By incorporating agile development practices and continuous delivery, Datopian helped the client optimize their data cataloging, discovery, and dataset quality initiatives, ultimately driving efficiency and innovation within their research and development teams. This solution facilitated the client's reproducible science and dataset quality initiatives while empowering global research and development staff with efficient data access and discovery.
Main technologies & tools used
Context
The Client is a fortune 500 company, one of the largest pharmaceutical corporations in the world, with a highly specialized Gene Research and Therapy division in Silicon Valley, California. As a highly advanced biotechnology organization, the client deals with large amounts of clinical trials data of many different provenances, data sources and storage factors, versions and origins. The operations they perform on these data are just as rich - from simple curation to improving and augmenting old data with new calculations and conclusions; from planly listing publicly available clinical trials data to using it as a baseline for designing and running internal clinical studies.
The situation
Being a very large, distributed organization with many teams and departments, the client was looking, first and foremost, for a complete solution to aggregate and build an easy-to-use discovery portal and a search engine for their entire datasets across the organization regardless of origin, storage or geographical boundaries. Also, as part of their strategic future plans, the client wanted to integrate their complex organization-specific metadata language system for discovery and predictable data manipulation, but also for enforcing and measuring dataset quality through those same metrics defined by the metadata language system (somewhat similar to industry standard ones such as Dublin Core and its derivatives).
Before approaching Datopian, the client did an extensive evaluation of several other competing solutions, which are mostly in the closed-source market. None of the solutions they evaluated were able to provide all of the criteria they had for the short-term and the long-term functionality, especially as a cross-organization dataset discovery portal.
The criteria
In the evaluation criteria the main themes for the chosen solution were: “immediately useful” and “extreme customizability”. While some of the closed-source solutions could fulfill the first requirement, almost no other than CKAN could allow the latter in a straightforward, incremental way. More precisely these were:
- Extensibility both in UI, appearance theme and logic (“Frontend & Backend”).
- Support distributed deployment and enabling access to data across organizational and geographically disparate boundaries.
- Future-proof; with a clear maintenance and security improvement path outlook.
- Support interoperability with existing industry databases, tools, languages and libraries.
- Have a well-defined HTTP API and support automation out of the box; And have a predictable straightforward way to extend and/or customize this API when the need arises.
- Support a dataset publishing domain model, with extensive modeling for the following elements:
- Organizations
- Groups (for grouping by case study or showcase)
- Relationships and Provenance between Data.
- Resources as a storage point for actual data or APIs and methods thereof, to access and collect said data.
- Datasets and their Versions.
- Support a sophisticated tagging system to enable arbitrary grouping of data and easier intelligent search-autocomplete style discovery including faceted search.
- Support automation in uploading new datasets.
The solution
Roles and Process
Work started in feature sprints of 2 weeks, where the client was still slowly adapting to a Scrum-based delivery process. As we have a Scrum-based agile approach to delivery, we have been instrumental in coaching and transferring Agile Development practices to the client.
The client has decided to outsource their project to an offshore IT and Development team to support their deployment platform administration and minor development needs.
Datopian Tech Lead would coordinate the requirements elicitation from the client’s product and business teams and would support the offshore IT team with CKAN deployment whilst extending knowledge in the first few months working towards the first milestone. The first milestone was to have an operational dataset portal where scientists and curators could add and modify datasets via CKAN’s Web UI, and use its search engine for dataset discovery.
In general, Datopian team would cater for all of the deep CKAN customization and features that required complex and deep architectures, whereas the offshore team would mostly take care of resolving deployment issues to their platform and availability of the CKAN Web App.
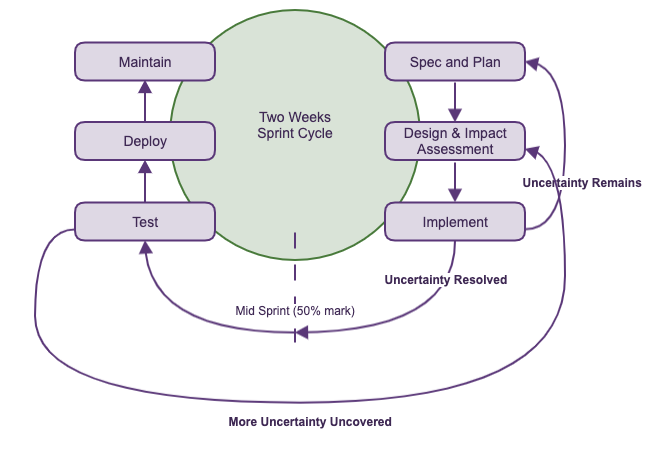
The process employed by Datopian was inspired and constrained in an agile development cycle, however due to the unique nature of the client (FDA regulated pharma firm) and the many internal interest groups in the project, a modified version of the process was practiced. Following a revised workflow allowed for rapid schedule and feature scope changes mid sprint.
This was achieved by allowing a buffer for items that there’s great uncertainty about or whose uncertainty did not resolve in the previous cycle. Thus allowing us to act upon new insights and newly resolved uncertainty mid sprint. This also allowed for flexibility in dealing with uncertainty uncovered during the testing process in the same sprint.
The process is outlined in the following diagram:
A notable challenge identified early in the process was establishing a common ground for communication over features, technical specifications and implementation ideas. This is quite common for companies whose main activity is not software production and came as no surprise - Datopian has extensive experience in implementing solutions for a wide range of government and corporate organizations with different levels of technical expertise. Especially when dealing with the specific field of data collection and data engineering.
The Teach Lead and the Datopian Product Owner were, in this regard, key to sharing knowledge so that in several sprints, the client could understand and communicate effectively on a common basis of understanding.
Requirements Reconciliation over Multiple Stakeholders
The Teach Lead and the Datopian Product Owner also played an important role as a focal point for the specifications and requirements of the many stakeholders - both technical and business. Datopian’s expertise as the creator of CKAN and a range of other data collection and engineering tools allows the client to be confident that the best possible result has been achieved in terms of technical feasibility.
Automated Testing and Continuous Delivery
When development kicked off, the client did not use format automated testing, but performed a more “traditional” manual approach. With the development of the workflow, Datopian has played an important role in training the client team to become proficient in automated testing, using modern tools and technologies relevant to the CKAN web application stack. Datopian's technical team passed on their knowledge of how to maintain large and complex projects with the best possible quality, provided tips and tricks, and transfer of knowledge to the client's team so that they become self-sufficient in this aspect. By the end of the first year, the project had grown into a comprehensive and sophisticated automated test suite that allowed for much faster development iterations and prevented from regressions of starting new features and experiments.
Hand in hand with the evolution of the test suite, Datopian also encouraged the client to switch to a more modern deployment and delivery approach. Thus employing tools like Jenkins, EKS and Containers for both delivery and development. The process went from ad-hoc manual building and deployment of developed software to fully automated process that is triggered by tagging a release branch in the code repository and letting automation build, test and deploy if all stages were successfully completed.
The outcome
Datopian worked with the client very closely. The Datopian team acted as part of the Global Product project team, as well as the Technical and Operational team.
This enabled Datopian to bring its entire skillset, expertise and knowledge in a transparent forward-looking way, supporting the client in both delivery and design and development. This in turn enabled the client to realize their exact goals and vision, and reach an end product they were highly satisfied with, which plays an important role in their planned long-term strategy to streamline their data cataloging and discovery story.
The end result is a highly customized, sophisticated CKAN based Web Portal and API serving system with unique “laser targeted” features making it a novel tool and the central piece in the client’s “Reproducible Science” and dataset quality initiative. It is currently used globally by its research and development staff.
Client Specific Domain Model and Metadata Language
One of the key points for the client to choose CKAN was the promise of extensibility and customizability. This trait of CKAN has proven to be instrumental as a tool for implementing and modeling the client’s complex metadata language, which describes human clinical studies, their provenance, inter- and outer-relationships with other datasets, other storage systems and repositories etc.
This also included a complex dataset quality rating system based on the very same principles of their bespoke metadata language.
The deep customization and extending of CKAN to that end happened in two layers:
- The presentation layer; i.e. the “FrontEnd” or the User Graphical Interface, where modifications took place to faithfully represent the client’s domain model in the context of the metadata language, and allow intuitive addition, search and manipulation of data thereof.
- The API layer; where novel development happened to create sophisticated API endpoints, enabling automation and headless manipulation of datasets, provenance and data relationships. This API is scheduled to replace the stock CKAN API for all of the clients’ operations against the portal as a dataset aggregation repository. More on this below.
Custom Harvesting Framework
To support automation around the highly complex custom metadata language of the client, a totally new API and ingestion framework had to be developed. This has been created from the ground up as a mostly separated service from the main CKAN core functionality, so it can be deployed as a separate microservice and operate agnostic of the Web front end facing instances.
The fact that CKAN is open source software and is a standard Python proved pivotal to make development of this software layer possible.
The parts of this endeavor included:
- Reviewing CKAN core code in the relevant parts to assess existing capabilities to build upon.
- Using existing Python libraries to implement the novel requirements such as Verified Linked JSON (JSONLD) to support the intricate inter-connections entities in the client’s metadata.
- Tapping into CKAN’s data revision system to implement novel data versioning, more on that below.
- Create bespoke support into CKAN Core to enable referencing parts of a datasets from itself, as required by the client’s metadata language (for example, from a dataset to it’s versions, from a resource to a dataset etc).
Dataset Versioning
One of the key elements of the client’s bespoke metadata language was the notion of “provenance”. The notion of the origins or the “line of heritage” of metadata items and the data itself.
As an FDA regulated pharmaceutical, it is essential to be able to track back the origins of clinical data, trials and the personnel who conduct or modify clinical data in the course of previous, but also the green field research projects and development.
The versioning layer Datopian has created for the client supports both automation through the harvesting framework and also version control and authoring from the CKAN UI which is novel and isn’t available as part of the CKAN core.
What’s next
Towards the end of the project we were happy to see that our coaching and knowledge transfer bore a lot of fruit. The client team became proficient in the entire lifecycle of software development, including automated testing, complex design, planning and impact assessment sessions that have improved the duration and quality of their deliverables.
Product and business teams now spoke using data engineering and collection terminology, and developed a sense and understanding of the amount of effort and prerequisites required to manage feature development in a predictable and timely manner.
Inspired by Datopian’s own style of software development and architecture, the client now plans to go even further and upgrade their stack with the following:
- Go further to break down the monolithic parts of the solution to microservice architecture.
- Utilise more services and products from the AWS cloud in support for the former.
- Upgrade their used Python version, and as such upgrade to the latest production version of CKAN (2.9).
- Completely switch to use the Harvesting Framework API instead of CKAN core API for all of the operations against the portal (and use the UI just for search and view).
Across the organization, their plan is to add more and more data departments and divisions to the solution to support all their scientific and administrative staff with quick and efficient access to their data.
Have a similar project and need help from the people who built CKAN, the world’s leading data management system? Contact us!
We create, maintain, and deploy data management and data engineering technologies for government, enterprise, and the non-profit sector using CKAN, Frictionless Data, DataHub.io and other open-source software that we have built ourselves.